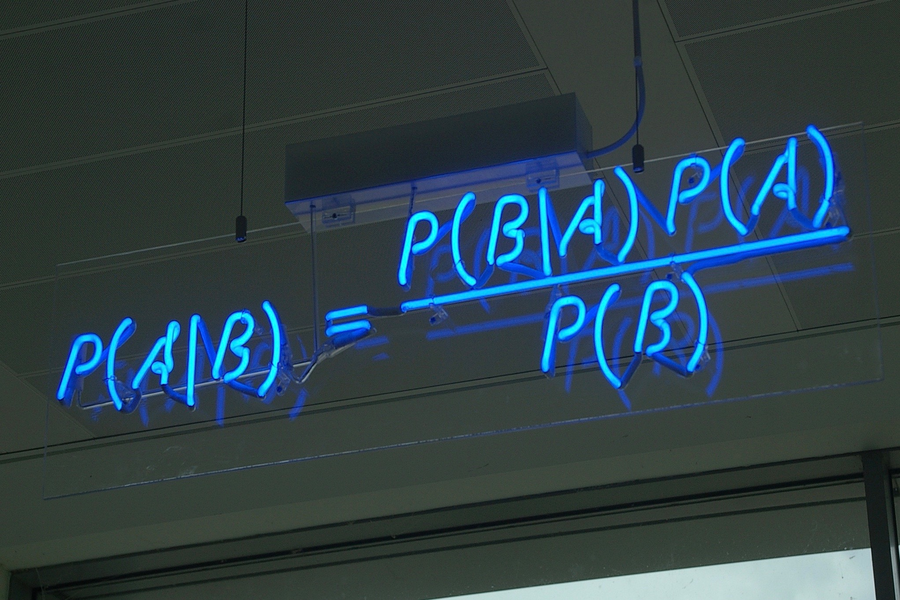
I have recently been interested in the field of epistemology, which is the branch of philosophy that deals with how we reliably form beliefs, or how we acquire knowledge. In particular, I have been interested in how we can quantify the strength of a particular piece of evidence, and how a cumulative case, involving many different lines of evidence, may be modeled mathematically. I have come to think of evidence in Bayesian terms and this has in turn impacted the way I think about the biological arguments for intelligent design.
What is Bayes’ Theorem?
Named for the 18th-century English Presbyterian minister Thomas Bayes, Bayes’ Theorem is a mathematical tool for modelling our evaluation of evidences to appropriately apportion the confidence in our conclusions to the strength of the evidence. Expressed in mathematical terms, small pieces of evidence, no single piece by itself of very great weight, can combine to create a massive cumulative case.
The strength of the evidence for a proposition is best measured in terms of the ratio of two probabilities, P(E|H) and P(E|~H) — that is, the probability of the evidence (E) given that the hypothesis (H) is true, and the probability of E given that H is false. That ratio may be top heavy (in which case E favors H), bottom heavy, or neither (in which case E favors neither hypothesis, and we would not call it evidence for or against H). Note that the probability of the evidence given your hypothesis does not need to be high for the data to count as evidence in favor of your hypothesis. Rather, the probability of the evidence only needs to be higher on the truth of the hypothesis than on its falsehood.
To take an example, suppose that P(E1|H) = 0.2, but P(E1|~H) = 0.04. Then the ratio P(E1|H)/P(E1|~H) has the value of 5 to 1, or just 5. If there are multiple pieces of independent evidence, their power accumulates exponentially. Five such pieces would yield a cumulative ratio of 3125 to 1. If the initial ratio were 2 to 1, ten pieces of independent evidence would have a cumulative power of more than 1000 to 1.
Application to Intelligent Design
How might this way of approaching evidence relate to intelligent design? In 2004 and 2005, Lydia McGrew (a widely published analytic philosopher) and her husband Timothy McGrew (chairman of the department of philosophy at Western Michigan University) published two papers in the journals Philosophia Christi and Philo, respectively. They set out how the case for intelligent design might be formulated in terms of a Bayesian inference. [1, 2] For non-technical readers, Lydia McGrew’s Philo article is the more accessible of the two.
While other approaches to constructing the design inference (such as Stephen Meyer’s inference to the best explanation, or William Dembski’s explanatory filter, which works by elimination of the null hypothesis of chance and physical necessity) have received widespread attention within the ID community, it is, in my opinion, unfortunate that the contributions of the McGrews are seldom discussed in the current conversation, at least as far as the life sciences are concerned. Certainly, the Bayesian approach to the design hypothesis has not received anything like the same level of adoption. I believe, however, that the method they propose of articulating the case for design is worthy of serious consideration.
When it comes to the argument for design based on the physical sciences, a Bayesian approach is much more popular. Luke Barnes (a theoretical astrophysicist, cosmologist, and postdoctoral researcher at Western Sydney University), for example, employs a Bayesian approach to the question of fine-tuning of the initial parameters of our universe. [3] This stands in contradistinction to the deductive formulation presented by William Lane Craig, which takes the following form:
Premise 1: Fine-tuning is due to either necessity, chance, or design.
Premise 2: Fine-tuning is not due to either necessity or chance.
Conclusion: Therefore, fine-tuning is due to design.
In contrast, the Bayesian formulation of the fine-tuning argument is typically presented along the following lines: Our universe shows extraordinary fine-tuning. For the cosmological constant alone the variability for life of any form to exist seems to be as low as 1 in 10120. If it were to be modified even slightly either the universe would expand so rapidly we would only ever get the two lightest elements of hydrogen and helium, or the universe would collapse in on itself, due to gravity, within picoseconds of the Big Bang. Either way, no life could exist.
The likelihood of unguided blind and unintelligent mechanisms producing such a precise and finely tuned feature is incredibly low. However, an intelligent agent is capable of thinking ahead with will, foresight, and intentionality to rapidly find rare and isolated solutions for the physical laws and constants that fit the requirement of a life-friendly universe. Therefore, the likelihood of an intelligent agent producing such precision in the physical laws and constants of our universe is much higher than the likelihood of blind, unintelligent mechanisms doing the same. In view, therefore, of the top-heavy ratio of P(E|H) and P(E|~H), the observation of fine-tuning counts as strong confirmatory evidence in favor of the hypothesis of cosmic intelligent design.
How can we apply this principle to the case for biological design? I propose that we construct the argument as follows: Given the hypothesis that living systems are the result of design, it is not extremely unlikely that biological systems would be rich in digitally encoded information content and irreducibly complex machinery (given that we know from experience with human agents that they often generate information and produce irreducibly complex contraptions). On the other hand, it is incredibly unlikely that such information-rich systems and irreducibly complex machinery could have arisen by an unguided natural process involving chance and physical necessity. Therefore, given that we in fact find such systems to be abundant in living cells, we may take the presence of such features as strong confirmatory evidence for the hypothesis of design over non-design.
God of the Gaps?
Does such an argument commit a God-of-the-gaps fallacy? Not at all. Considering why can, in fact, be quite instructive for understanding the nature of Bayesian inferences. As Lydia McGrew explains in her paper in the journal Philo, it is easy to conceive of a scenario where we know the likelihood on the hypothesis of chance is very low, but nonetheless we do not have evidence for the likelihood on the hypothesis of design being higher. For instance, suppose we were to find a small cloud of hydrogen molecules floating in interstellar space in which the molecules were not dispersing. Without sufficient mass for the cloud to be held together by gravity, such an observation would be an anomaly given our present understanding of physics. However, even though such an observation would be seemingly improbable on the hypothesis of natural law, there would be no reason to think that the hypothesis of design is a better explanation. After all, there is no independent reason to think that a designer would likely cause a small cloud of hydrogen molecules to clump together.
McGrew further points out that it would be quite a different story if, in the distant future, we were able to capture high resolution images of Alpha Centauri (the closest star after the sun) and discover that a Volkswagen Beetle was orbiting a planet there. In that case, the probability of a Volkswagen Beetle being there would be much, much higher on the hypothesis of design than on its falsehood.
A Consideration of Prior Probability
No discussion of Bayes’ Theorem can be complete without a consideration of the prior probability. Prior probability relates to the intrinsic plausibility of a proposition before the evidence is considered. Normally the prior probability will be somewhere between zero and one. A prior probability of one means that the conclusion is certain. For instance, the fact that two added to two is equal to four has a prior probability of one. It is definitionally true. A prior probability of zero, conversely, means that the hypothesis entails some sort of logical contradiction (such as the concept of a married bachelor) and thus cannot be overcome by any amount of evidence.
Priors can be established on the basis of past information. For example, suppose we want to know the odds that a particular individual won last week’s Mega Millions jackpot in the United States. The prior probability would be set at 1 in 302.6 million since those are the odds that any individual lottery participant, chosen at random, would win the Mega Millions jackpot. That is a low prior probability, but it could be overcome if the supposed winner were to subsequently quit his job and start routinely investing in private jets, sports cars, and expensive vacations. Perhaps he could even show us his bank statement, or the documentary evidence of his winnings.
Those different pieces of evidence, taken together, would stack up to provide powerful confirmatory evidence sufficient to overcome a very small prior probability to yield a high posterior probability that the individual did indeed win the Mega Millions jackpot. In other situations, setting an objective prior is more tricky, and in those cases priors may be determined by a more subjective assessment. In my own arguments, I tend to set the prior probability generously low, to err on the side of caution. In the case of ID, however, one could argue that the prior probability of design is raised significantly by the evidence of cosmic fine-tuning.
The Advantages of a Bayesian Approach to ID
Structuring the argument in the way I have proposed above in fact helps us to address some popular objections to intelligent design. For example, consider the argument from suboptimal design, which I have addressed at Evolution News before (e.g., see here and here). This argument concerns the supposed unlikelihood that a designer would create biological structures that appear to be imperfect, such as the circuitous route of the recurrent laryngeal nerve. However, when you consider evidence as a likelihood ratio of P(E|H) and P(E|~H), this argument quickly loses its force. Even if we concede that given examples of suboptimal design are improbable on the hypothesis of design, they are still, I would suggest, more probable on the hypothesis of design than on its falsehood. Therefore, even granting a very low probability to the existence of apparently sub-optimally engineered systems on the hypothesis of design, such systems still count as evidence for design rather than against it.
Another popular objection to design as an inference to the best explanation is that we only possess uniform and repeated experience of human agency. We do not have experience with non-human designers, much less non-material ones (which, in my judgment, any plausible contender for the role of designer would have to be). However, as Lydia McGrew points out, “Any attempt to use frequencies, either to make a straight inductive inference or to construct a likelihood for a Bayesian inference, must confront the problem of induction” (McGrew, 2004). In other words, it is always a possibility that a group which has some characteristic that differs in some way from the sample already analyzed differs also with respect to the very quality about which we are interested.
McGrew gives the analogy that there is always a possibility that prehistoric civilizations did not have the ability or desire to make arrowheads. Nevertheless, if we discover arrowheads that date to prehistoric times, it becomes irrational to reject the inference that the prehistoric arrowheads were produced by an intelligent agent simply due to the fact that he lived in a time period different from the other makers of arrowheads with which we are familiar. Why then, asks McGrew, should there be special hesitation about a similar use of induction when it comes to extrapolating from a known group to an unknown group in the ID debate? Why should the gap between human and non-human agents be of greater epistemic significance than that between human agents living in different time periods? It seems to be quite arbitrary.
The same principle may be applied to the objection that we have never observed intelligent agents design living objects, even those which are information rich and contain irreducibly complex machinery. As McGrew again points out, reference class difficulties always occur when induction is used. Indeed, an event or object may always be defined in such a way so as to make it unique with respect to some of its properties.
Conclusion
To conclude, I submit that Bayes Theorem represents a powerful way to model and structure one’s thinking, especially about proportioning one’s confidence in a conclusion relative to the strength of the available evidence, as well as informing one how one ought to update one’s belief in response to new evidence.
The Bayesian formulation of biological design arguments is, in my opinion, deserving of greater attention. Bayesian inference is widely used when dealing with design in the physical sciences. Perhaps the time has come for this structure of argument also to be used in design arguments in the life sciences.
Footnotes
[1] McGrew, L. (2004) “Testability, Likelihoods, and Design.” Philo 7(1):5-21.
[2] McGrew, Timothy. (2005) “Toward a Rational Reconstruction of Design Inferences.” Philosophia Christi 7:253–98.
[3] Barnes, L.A. (2018) “Fine-tuning in the context of Bayesian theory testing.” European Journal for Philosophy of Science 8:253-269.